 Anoxinon e.V.
Anoxinon e.V. 

Microsoft has partnered with Anthropic to develop an official C# SDK for the Model Context Protocol (MCP) - an open protocol designed to connect large language models ( #LLMs) with external tools & data sources.
Explore more: https://bit.ly/42rusbA


Microsoft has partnered with Anthropic to develop an official C# SDK for the Model Context Protocol (MCP) - an open protocol designed to connect large language models ( #LLMs) with external tools & data sources.
Explore more: https://bit.ly/42rusbA
Unlocking AI Potential: The New Anthropic Ruby API Library
The newly released Anthropic Ruby API library offers developers seamless integration with the Anthropic REST API, empowering Ruby applications to leverage advanced AI capabilities. With features like ...
https://news.lavx.hu/article/unlocking-ai-potential-the-new-anthropic-ruby-api-library


 Нове дослідження Microsoft #Research виявило, що навіть передові ШІ-моделі o1 від #OpenAI та Claude 3.7 Sonnet від #Anthropic здатні виправляти помилки в коді не більше ніж у половині випадків. Тестування проводилося на базі бенчмарку SWE-bench.
Нове дослідження Microsoft #Research виявило, що навіть передові ШІ-моделі o1 від #OpenAI та Claude 3.7 Sonnet від #Anthropic здатні виправляти помилки в коді не більше ніж у половині випадків. Тестування проводилося на базі бенчмарку SWE-bench.
В ході експерименту ШІ-агенти намагалися вирішити 300 завдань, які стосувались налагодження коду. Лідером стала модель Claude 3.7 Sonnet, яка виконала завдання з успішністю на 48,4%, друге місце посіла OpenAI o1 (30,2%), третє – o3-mini (22,1%).

#KI, #Anthropic, #Preis
Teurer Spaß oder lohnendes Geschäft? Premium-Chatbot für 200 Dollar/Monat. https://www.linux-magazin.de/news/premium-chatbot-fuer-200-dollar-monat

Researchers concerned to find AI models hiding their true “reasoning” processes - Remember when teachers demanded that you "show your work" in school? Some ... - https://arstechnica.com/ai/2025/04/researchers-concerned-to-find-ai-models-hiding-their-true-reasoning-processes/ #largelanguagemodels #simulatedreasoning #machinelearning #aialignment #airesearch #anthropic #aisafety #srmodels #chatgpt #biz #claude #ai

AI-Chatbot Claude: Anthropic bietet Max-Abonnement für Vielnutzer https://www.computerbase.de/news/apps/ai-chatbot-claude-anthropic-bietet-max-abonnement-fuer-vielnutzer.92148/ #Anthropic #Claude3

After months of user complaints, Anthropic debuts new $200/month AI plan - On Wednesday, Anthropic introduced a new $100- to $200-per-month subscript... - https://arstechnica.com/ai/2025/04/anthropic-launches-200-claude-max-ai-plan-with-20x-higher-usage-limits/ #largelanguagemodels #machinelearning #aiassistants #chatgptpro #anthropic #claudemax #claudepro #chatgpt #chatgtp #biz #claude #openai #ai

Read about an LLM internals. How it's not reasoning, how it's not doing math at all, and how you are fooled and how you can fool it.
https://transformer-circuits.pub/2025/attribution-graphs/biology.html
If you prefer a quick TL;DR:
https://www.youtube.com/watch?v=-wzOetb-D3w
Kürzlich erschien in #t3n ein Artikel über die seltsamen "Denk"-Prozesse der #LLM's und wie wenig man davon weiß:
KI-Blackbox geknackt: Anthropic enthüllt, wie Claude wirklich denkt – und es ist bizarr
[https://t3n.de/news/ki-blackbox-anthropic-geknackt-1680603/]
mit 2 Kernaussagen:
1
"Kaum eine Technik, die so breit eingesetzt wird, wurde jemals so wenig verstanden – wenn nicht sogar noch nie eine."
2
"LLMs sind seltsam und man sollte ihnen nicht trauen."
In #Midjourneyv7 sieht das so aus... 






Chain-of-thought reasoning to improve LLMs is like reducing the time step of an Euler discretisation in a fluid dynamics simulation. It's a simple and computationally expensive way to get more detail and better convergence to the wrong answer.
**Reasoning models don't always say what they think**
https://www.anthropic.com/research/reasoning-models-dont-say-think
Manchmal wünscht man sich doch, in die Köpfe anderer Menschen hineinschauen zu können. Anthropic hat zwei Methoden entdeckt, wie das bei Sprachmodellen gelingen könnte.
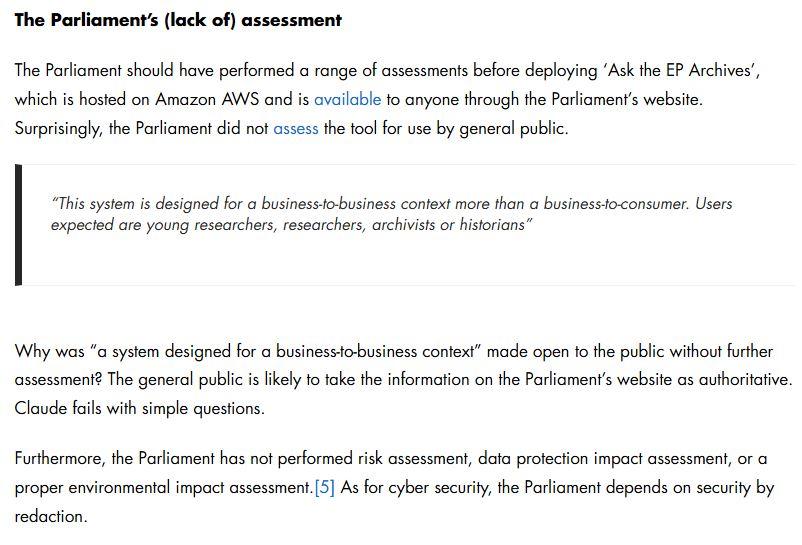
Last year #European Parliament Archive unit head appeared in promo videos for Anthropic when EP began using #Anthropic's #AI model.
ICCL Enforce investigated.
There are no contracts. No impact assessment. No bias checks. Blind faith in Constitutional AI and #Amazon lock-in.
Anthropic erforscht LLMs und entdeckt dabei unerwartet bizarre Ergebnisse | heise online
https://heise.de/-10334400 #KI #Anthropic #Sprachmodell #LLM #Mathematik

Tracing the thoughts of a large language model https://www.anthropic.com/news/tracing-thoughts-language-model #AI #GenAI #Anthropic #LLM
MCP: The new “USB-C for AI” that’s bringing fierce rivals together - What does it take to get OpenAI and Anthropic—two competitors in the AI as... - https://arstechnica.com/information-technology/2025/04/mcp-the-new-usb-c-for-ai-thats-bringing-fierce-rivals-together/ #modelcontextprotocol #largelanguagemodels #machinelearning #anthropic #chatgpt #chatgtp #biz #openai #api #mcp #ai
Manchmal wünscht man sich doch, in die Köpfe anderer Menschen hineinschauen zu können. Anthropic hat zwei Methoden entdeckt, wie das bei Sprachmodellen gelingen könnte.
"Why do language models sometimes hallucinate—that is, make up information? At a basic level, language model training incentivizes hallucination: models are always supposed to give a guess for the next word. Viewed this way, the major challenge is how to get models to not hallucinate. Models like Claude have relatively successful (though imperfect) anti-hallucination training; they will often refuse to answer a question if they don’t know the answer, rather than speculate. We wanted to understand how this works.
It turns out that, in Claude, refusal to answer is the default behavior: we find a circuit that is "on" by default and that causes the model to state that it has insufficient information to answer any given question. However, when the model is asked about something it knows well—say, the basketball player Michael Jordan—a competing feature representing "known entities" activates and inhibits this default circuit (see also this recent paper for related findings). This allows Claude to answer the question when it knows the answer. In contrast, when asked about an unknown entity ("Michael Batkin"), it declines to answer.
Sometimes, this sort of “misfire” of the “known answer” circuit happens naturally, without us intervening, resulting in a hallucination. In our paper, we show that such misfires can occur when Claude recognizes a name but doesn't know anything else about that person. In cases like this, the “known entity” feature might still activate, and then suppress the default "don't know" feature—in this case incorrectly. Once the model has decided that it needs to answer the question, it proceeds to confabulate: to generate a plausible—but unfortunately untrue—response."
https://www.anthropic.com/research/tracing-thoughts-language-model
 BREAKING: Super-smart AI can't catch 'em all! Despite being able to simulate the entirety of human knowledge, Anthropic's #Claude is still stumped by a children's game. Maybe it should try turning its digital cap backwards.
BREAKING: Super-smart AI can't catch 'em all! Despite being able to simulate the entirety of human knowledge, Anthropic's #Claude is still stumped by a children's game. Maybe it should try turning its digital cap backwards. 
https://arstechnica.com/ai/2025/03/why-anthropics-claude-still-hasnt-beaten-pokemon/ #AIfail #Anthropic #GamingNews #TechHumor #HackerNews #ngated





















